- Published on
🧰 The Role of Activation Functions in Neural Networks
- Authors

- Name
- Van-Loc Nguyen
- @vanloc1808
🧰 The Role of Activation Functions in Neural Networks
Activation functions are the unsung heroes of deep learning. Without them, neural networks would simply be stacks of linear operations - no matter how deep. In this post, we dive into how activation functions work, why they're essential, and how to choose the right one for your model.
🔍 Why Do We Need Activation Functions?
Imagine a neural network without activation functions - it's just a big linear equation. No matter how many layers you stack, the output remains a linear function of the input.
Activation functions introduce non-linearity, enabling networks to approximate complex functions like:
- Image recognition
- Natural language processing
- Reinforcement learning
Mathematically, an activation function ( f(x) ) transforms the output of each neuron before passing it to the next layer.
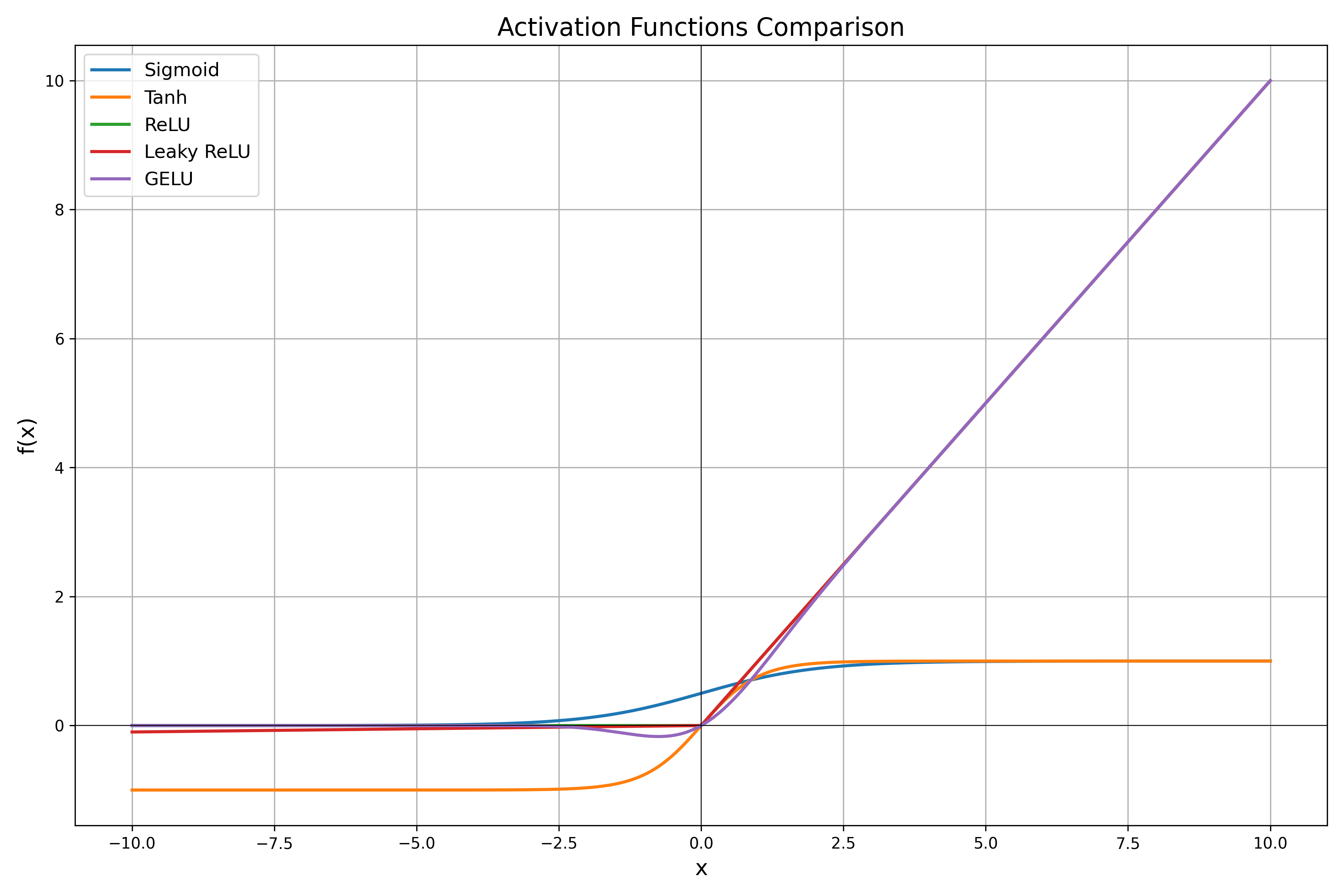
🔢 Common Activation Functions
Let's walk through the most popular activation functions, their formulas, use cases, and limitations.
1️⃣ Sigmoid
- Range: (0, 1)
- Use Case: Binary classification (logistic regression)
- Drawback: Saturates for large , causing vanishing gradients
2️⃣ Tanh
- Range: (-1, 1)
- Use Case: Often preferred over sigmoid in hidden layers
- Drawback: Still suffers from vanishing gradients
3️⃣ ReLU (Rectified Linear Unit)
- Range: [0, ∞)
- Use Case: Default choice for hidden layers in CNNs and MLPs
- Advantages: Computationally efficient, sparse activation
- Drawback: Dying ReLU problem - neurons may output zero permanently
4️⃣ Leaky ReLU
- Fixes ReLU's dying neuron problem by allowing a small slope in the negative region ()
5️⃣ GELU (Gaussian Error Linear Unit)
Where is the cumulative distribution function of the standard normal distribution.
- Use Case: Transformers (e.g., BERT, GPT)
- Advantage: Smooth and differentiable; works well in large LLMs---
📊 Visual Comparison of Activation Functions
🙏 Acknowledgments
Special thanks to ChatGPT for enhancing this post with suggestions, formatting, and emojis.